定序的迭代
「定序」就是將一段序列判讀出 ATCG 排列的順序,「迭代」則是為了接近最終目標而反覆改良的過程。為了能精準有效率知道生物的基因序列,DNA 定序技術一代一代的不斷精進改良。
定序的歷史其實很有趣,從利用嗜菌體定序、2D電泳,人類基因組計畫之民間與政府的技術競賽,故事於網路上資源相當多就不再贅述。這邊則以 1977 年 Sanger 大師發明 Chain-termination 為界線,往後介紹人類解開生物程式碼的逆向工程。
第一代定序 Sanger Sequencing
又名 Sequencing-Based Typing
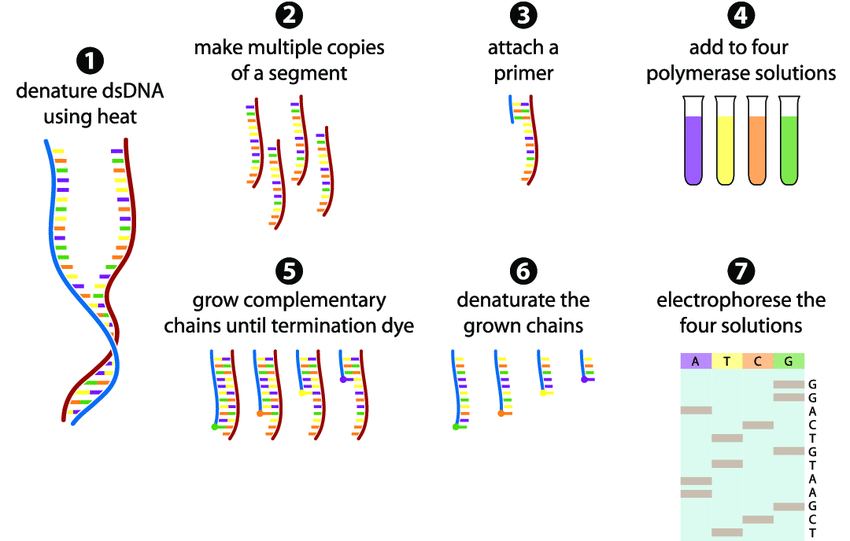
- 將樣本加熱,使 DNA 雙股打開
- 將有興趣的片段複製變多,以此得到一大堆有興趣的片段 (用一般的 PCR 放大特定片段)
- 加上引子 (Primer)
- 準備 4 個管子,皆含有聚合酶,dNTP,
但分別加入 ddATP、ddTTP、ddCTP、ddGTP 在不同管子 (以4種顏色示意) - 開始合成 (PCR),過程中聚合酶合成某片段時,若抓到 ddNTP 的材料,會使得下一個 cycle,該片段因聚合酶無法繼續延長而終止
- 因為遇上 ddNTP 的機率是隨機,最終管內會有長度不一個 DNA 片段 (末端含有 ddNTP ),然後將原始 Template (模板)移除
- 把 4 個管分別跑在不同 well 的膠上,開始跑電泳~
- 由下往上讀,就是目標DNA的序列啦!
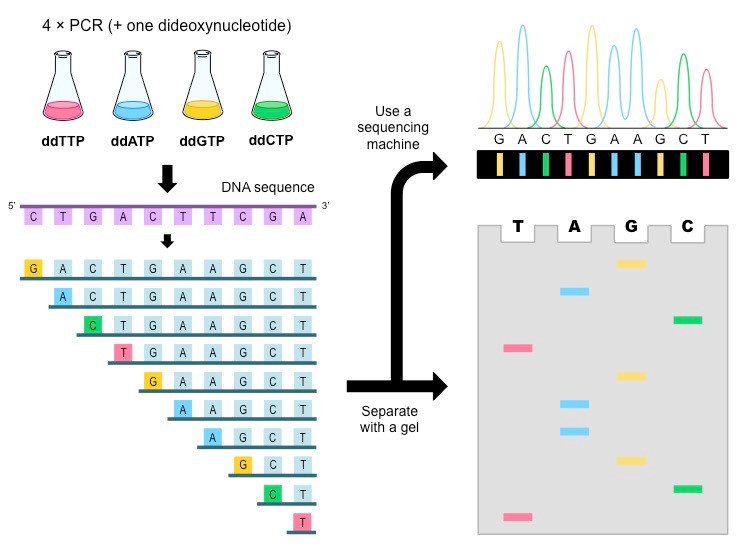
其採用的原理是 Chain-termination,也就是藉由合成中終止的方式,獲得長度不一片段,用跑膠判斷序列:
次世代定序 NGS – 以 Illumina 為例
為了解決長片段、大量定序需求以及效率低落等等心累的問題,經歷多家廠商的競爭,Illumina 公司開發的新技術成功打贏市場,目前 RNA seq、Single cell sequencing、Whole genome sequencing、Metagenomic (16S, 18S 等等),主流都採用 Illumina 的 NGS,他們的原理相同,差別在於樣本的前處理 (e.g 轉 cDNA or 夾16S) 以及後續分析軟體的流程。而 Illumina 採用的原理是 Bridge amplification + Sequencing by Synthesis (SBS),

接下來,了解下列步驟非常重要,因為後續分析會用到步驟中很多的觀念 :
Part A – 前處理
- 將 DNA 樣本打碎 (約 80 bp) (第一次看到先打碎序列其實蠻反邏輯的XD
- 加入Adapters,並使用連接酶加在序列片段頭尾 (可以想像改良過的 Primer,差別是頭尾都有,後續可以幫助放大片段)


- Adapters = 目標序列結合位 (sequencing binding site) (綠)
- indices(黃、紅) + oligos 互補序列 (紫、藍)
oligos 互補序列就是為了跟草皮 (lawn) 小草 (oligos) 結合 - indices 又名 index,帶有 barcode,每個 DNA 樣本都會有獨特的條碼。能同時將不同樣本放在同一個 Flow cell 多樣本大量定序,這樣子 Pooling 的方式稱為 Sample Multiplexing。像是大家帶著條碼手環泡在大眾池,這動作英文稱為 pooling,然後再拿著條碼器 (定序) 快速逼手環就知道誰是誰了。
- 帶有 Adapters 序列片段與 oligos 結合

- 聚合酶開始複製,使得草皮上的 oligos 被延長 後也長得與序列片段相同。被延長後的 oligos 稱為 Hybridized fragment (雜合片段),再將原序列片段洗去,他不要了,只留下 lawn上的雜合片段。

- 因為另一端也與 lawn 上 oligos 互補,所以雜合片段會彎腰結合,形成像是橋 (Bridge) 狀的序列,接著聚合酶又來複製了,形成兩座 DNA 橋 (Double stranded bridge)

- 重複第 4~5 很多很多次,形成上百萬座橋

- 稱為橋式放大(Bridge amplification)。
- 然後就會獲得很多根巧克力棒,洗去紫色底座 oligos 上的雜合片段,留下藍色底座 oligos 上的雜合片段

- 紫色底座的序列都飛走惹,剩下藍色底座。
Part B – Forward 端定序
- 在開始定序前,3′ 端的 oligos 會用一小段序列擋住,因為這段序列是加上去的,不需要被定序,接下來,帶有四種螢光的 dNTP 加入到 Flow cell 中,只要結合到雜合片段,就會發光 ! 稱為 Sequencing by Synthesis (SBS) ,因為一邊合成一邊定序。

- 電腦就會偵測螢光出現的順序,進行讀取,其實超級漂亮的 !!

- 加入一段能辨識 indices 的 primer,再加入dNTP 與聚合酶,一樣用螢光讀取的方式獲得這些目標序列的 barcode。

- 稱為 Index Read。
- 洗去indices的primer 還有各種一切,留下巧克力棒 (Hybridized fragment),Forward 定序讀完了,來讀 Reverse

- 稱為 Paired-End Sequencing。
Part C – Reverse 端定序
- 雜合片段彎腰與另一個 oligos 結合,並加入dNTP與聚合酶,
獲得 Reverse 的 Index (與 Forward Index相同) - 可愛聚合酶又登場啦,延長形成兩座 DNA 橋 (Double stranded bridge),
其實有上百萬對橋 - 與 7. 相反,這次洗去 Forward oligos 上的雜合片段,
留下 Reverse oligos 上的雜合片段 - 同 8.,oligos 會用一小段序列去擋住,
因為這段序列是加上去的,不需要被定序 - 同 9.,一邊合成一邊定序 因為步驟與 Part C 類似,就不放動畫了,有興趣可以觀看 Illumina出品 的動畫。
Part D 初步資料分析
- Illumina 會利用演算法將這些上述 Barcode、80 bp 的破碎序列資訊,
分類並組成一條一條完整序列,
最終長度則是依照給予的樣本為定,
以本系列文章為例,我們選擇 16S V3~V4區域,
每個檔案的就會含有數萬條長度為 250 bp 的序列,
並且每個樣本會有 2 個檔案,
因為 Paired-End Sequencing 含有 Forward 與 Reverse,
檔案內也會根據螢光偵測到的波型完整度,
給予每個 mer 判定後的品質分數 (Quality score)。